

SARINYAPINNGAM/iStock by way of Getty Photos
The artwork and science of modeling returns of economic assets is endlessly unsatisfying since no a person design completely captures the genuine actions of asset performances. As a final result, there will come a point when researchers are compelled to select a poison that seems less mistaken than the options.
Subjectivity on this front is unavoidable for any number of responsibilities in portfolio administration and design and style. From simulating to forecasting and past, each individual modeling physical exercise in finance tends to come down to employing a established of approximations that do not offend our anticipations also harshly.
As a very simple case in point, take into consideration the distribution of US fairness sector returns. Are they usually distributed? The solution is dependent on the time window. In transform, the implications forged a extensive shadow on what you can, and won’t be able to, fairly achieve with modeling.
Look at how a person-working day returns are dispersed by using SPDR S&P 500 (SPY), an ETF proxy for the US inventory market (based mostly on details for 1993-2022). In the chart under, it really is apparent that returns are fundamentally symmetric close to . SPY’s one particular-working day performances will not particularly match a theoretically pure random distribution (crimson line), but they are close ample so that most of the time, and for most modeling apps, you can presume normality prevails.
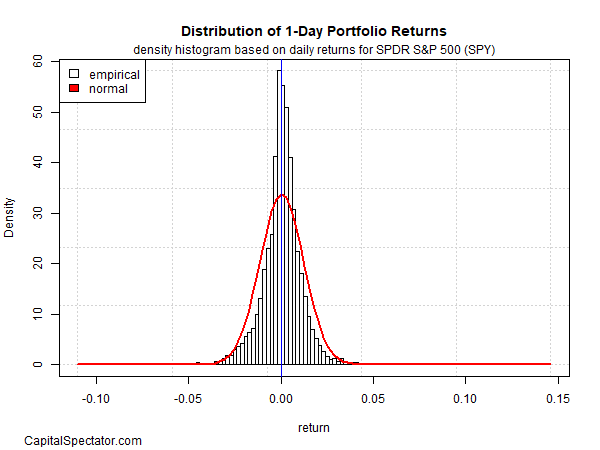
This assumption has a huge assortment of implications. For example, if a person-working day returns intently abide by a typical distribution, forecasting one particular-day returns is futile, at least most of the time.
But you can find very little normal about the 1-yr return distribution for SPY, as the next chart reminds. The benefits are positively skewed and there’s a clear incidence of unwanted fat tails. The a single-yr distribution, in small, tells a really different tale from a single-day returns and so the possibilities for this time window are pretty unique vs. just one-day success.
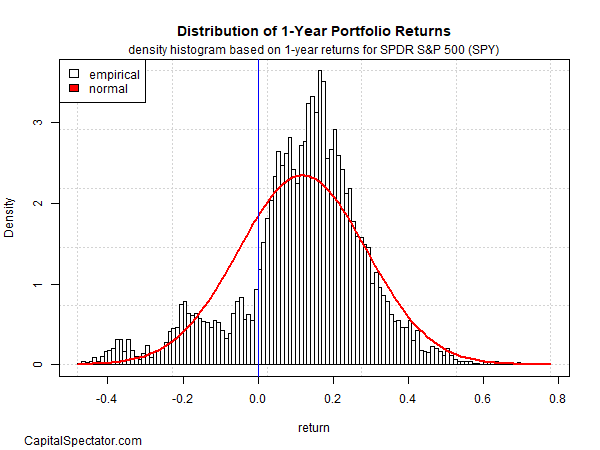
As a person instance, the difference indicates that one particular-yr returns provide the foundation for somewhat dependable forecasts. You never require a Ph.D. in finance to see that your odds are forecasting achievements are noticeably higher with a one-12 months time horizon vs. one working day. Or probably it can be much more exact to say that you happen to be very likely to be much less incorrect with a single-yr forecasts vs. one particular-working day estimates.
But although a single-working day returns are around random, they’re not flawlessly random. While it really is difficult to see in the distribution chart previously mentioned, a person-day changes have excess fat tails – fairly severe outcomes that run afoul of a regular distribution. For a clearer look at on this entrance, we can run a Q-Q plot, or quantile-quantile plot, which compares the empirical info (black circles) with a theoretical distribution – in this case, a regular distribution (red line).
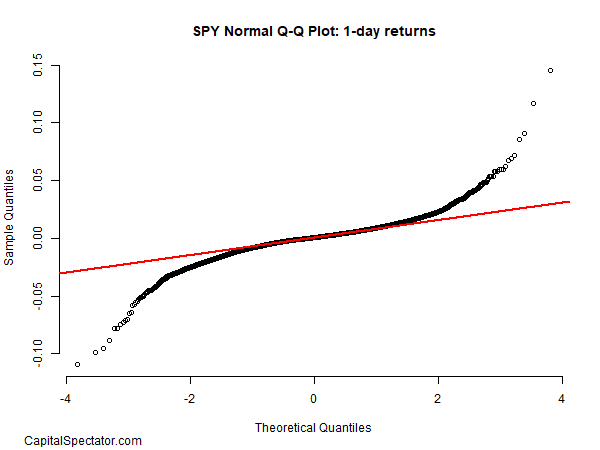
If SPY’s 1-day returns had been completely typical, they’d match the pink line. That’s legitimate for a considerable part of the knowledge established, but at the extremes, there are very clear divergences. On the still left facet, every day losses are a lot steeper than anticipated in a ordinary distribution. The opposite is genuine for rather huge gains.
A related profile applies to the just one-yr success. The major takeaway: departures from the ordinary distribution recommend that forecasting, simulating, and other modeling duties can be improved by factoring in body fat tails and other features applicable to non-normal distributions.
But chance is a two-sided coin. If you are not going to use a typical distribution to product the details, which distribution is appropriate? There are quite a few opportunities, and each and every arrives with its possess set of professionals and disadvantages. The obstacle is that no issue which distribution design you select, it will be improper in some diploma. Inspite of many years of investigate, no a single has nonetheless discovered or designed a distribution that perfect matches how equity returns vary in the serious planet.
That evokes some scientists to adhere with the historic document, which relieves us of the require to find a unique model. But that qualified prospects to its possess established of challenges. Simulating returns centered on the historic record is easy and arguably accurate, but there are worries with determining how to retain the serial correlation of money time series, for instance.
Just about every time you resolve 1 obstacle in modeling industry returns, risk and other aspects of economic assets, you make yet another problem. No surprise, then, that transferring nearer to a perfect model, when eternally elusive, typically needs modeling from numerous views and maybe utilizing ordinary outcomes as a benchmark.
“All versions are wrong, but some are valuable,” the statistician George Box famously quipped. Choosing which types are handy, or not, continue to consists of a significant dose of instinct and subjectivity. No matter how long you torture the data, it never tells you all the secrets and techniques you are desperate to listen to.
Editor’s Notice: The summary bullets for this short article have been preferred by Trying to find Alpha editors.







